Loading... 2023年9月19日,Oracle公司发布了Java的下一个LTS版本21,在这次更新中带来了15个JEPs > 官方文档地址 [JDK 21 Release Notes](https://yooss.cn/tool/java21/docs) --- ## 顺序集合(Sequenced Collections) 新的接口定义了一个有顺序的集合(encounter order),提供方法获取第一个元素和最后一个元素,在集合的头部或者尾部插入和删除元素,以及逆序遍历集合等,在一定程度上减少了部分不必要的操作 这样的接口有三种`SequencedCollection`,`SequencedSet`,`SequencedMap` 这是一个有关List的示例 ```java //使用List接口 List<Integer> list = new ArrayList<>(Arrays.asList(1, 2, 3, 4, 5)); //获取第一个元素 list.get(0); //获取最后一个元素 list.get(list.size() - 1); //使用SequencedCollection接口 SequencedCollection<Integer> list1 = new ArrayList<>(Arrays.asList(1, 2, 3, 4, 5)); //获取第一个元素 list1.getFirst(); //获取最后一个元素 list1.getLast(); ``` 当然,加入了新的类之后,Java中有关集合的结构图也有所改变 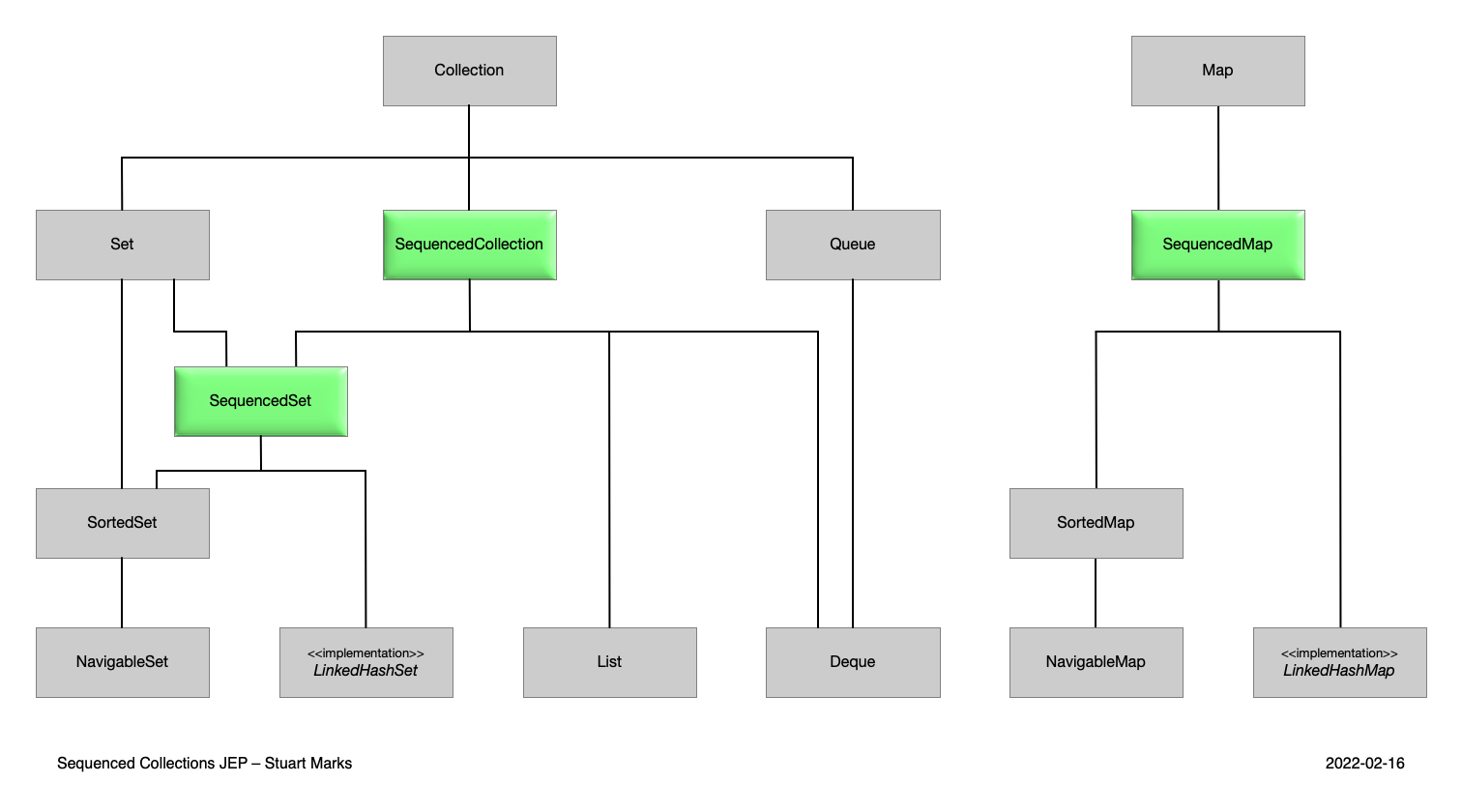 ## 记录模式匹配(Record Patterns) 该特征主要是对JDK 16中引入的Record类进行的补充,可以让我们更方便的提取记录中的值,具体用法如下 ```java record Point(int x, int y) {} //Java 16 static void printSum(Object obj) { if (obj instanceof Point p) { int x = p.x(); int y = p.y(); System.out.println(x + y); } } //Java 21 static void printSum2(Object obj) { if (obj instanceof Point(int x, int y)) { System.out.println(x + y); } } ``` ## Switch模式匹配(Pattern Matching for switch) 在日常的开发中,我们时常需要将一个对象与多个可能值进行匹配,在之前,我们可能会通过以下方式进行比较 ```java // Prior to Java 21 static String formatter(Object obj) { String formatted = "unknown"; if (obj instanceof Integer i) { formatted = String.format("int %d", i); } else if (obj instanceof Long l) { formatted = String.format("long %d", l); } else if (obj instanceof Double d) { formatted = String.format("double %f", d); } else if (obj instanceof String s) { formatted = String.format("String %s", s); } return formatted; } ``` 这样的代码样式受益与JDK 16中引入的模式匹配,但是这远远不够优美,因为我们使用了一种过于普通的结构`if-else`,这种结构带来的后果就是可能会产生某些隐式的错误,编辑器只会按照顺序来执行,其中的某些代码块可能很少执行,或者甚至没有执行,也就是说这段代码会有O(n)的复杂度,即使很多时候我们只需要O(1) 而现在,在JDK 21中,switch语句允许与模式匹配 ```java // As of Java 21 static String formatterPatternSwitch(Object obj) { return switch (obj) { case Integer i -> String.format("int %d", i); case Long l -> String.format("long %d", l); case Double d -> String.format("double %f", d); case String s -> String.format("String %s", s); default -> obj.toString(); }; } ``` 但是这样会带来新的问题,使用模式匹配会带来更大的结果集范围,比如匹配到了String类型,如果还需要匹配String的值,我们可以使用这样的代码 ```java // As of Java 21 static void testStringOld(String response) { switch (response) { case null -> { } case String s -> { if (s.equalsIgnoreCase("YES")) System.out.println("You got it"); else if (s.equalsIgnoreCase("NO")) System.out.println("Shame"); else System.out.println("Sorry?"); } } } ``` 显然,这不够优雅,我们有更好的选择 ```java // As of Java 21 static void testStringNew(String response) { switch (response) { case null -> { } case String s when s.equalsIgnoreCase("YES") -> { System.out.println("You got it"); } case String s when s.equalsIgnoreCase("NO") -> { System.out.println("Shame"); } case String s -> { System.out.println("Sorry?"); } } } ``` 或者可以直接给case增加更多的选择 ```java // As of Java 21 static void testStringEnhanced(String response) { switch (response) { case null -> { } case "y", "Y" -> { System.out.println("You got it"); } case "n", "N" -> { System.out.println("Shame"); } case String s when s.equalsIgnoreCase("YES") -> { System.out.println("You got it"); } case String s when s.equalsIgnoreCase("NO") -> { System.out.println("Shame"); } case String s -> { System.out.println("Sorry?"); } } } ``` ## 虚拟线程(Virtual Threads) 在之前版本中Java的多线程基于的是操作系统线程,而操作系统线程的数量是非常有限的,过高的成本,使我们不能有太多的线程。如果每个请求都消耗一个线程,从而消耗一个操作系统线程,则线程数通常会在其他资源(如 CPU 或网络连接)耗尽之前很久就成为限制因素。即使将线程池化,也会发生这种情况,因为池化虽然有助于避免启动新线程的高成本,但不会增加线程总数 而最新引入的虚拟线程是由JDK提供,你可以把它看作是在操作系统线程基础上创建的“一批”线程,它们有效地共享操作系统线程的资源,从而提升系统利用率,并不受数量限制,由于成本降低,所以虚拟线程不需要池化 参考以下代码,对比虚拟线程与传统线程的区别,使用ThreadMXBean接口获取当前系统线程数 在使用虚拟线程调用10000个线程时,系统级线程的数量为17 ```java try (var executor = Executors.newVirtualThreadPerTaskExecutor()) { IntStream.range(0, 10000).forEach(i -> { executor.submit(() -> { Thread.sleep(Duration.ofSeconds(1)); return i; }); }); System.out.println(ManagementFactory.getThreadMXBean().getThreadCount()); } ``` 在使用传统方法调用10000个线程时,系统级线程的数量为10008 ```java try (var executor = Executors.newCachedThreadPool()) { IntStream.range(0, 10000).forEach(i -> { executor.submit(() -> { Thread.sleep(Duration.ofSeconds(1)); return i; }); }); System.out.println(ManagementFactory.getThreadMXBean().getThreadCount()); } ``` ## ZGC垃圾回收机制(Generational ZGC) 简单的说就是性能更加好的垃圾回收机制,加入了“分代”。但是在目前版本中默认的垃圾回收机制还是非分代式,想要使用新特征要手动添加启动参数`-XX:+UseZGC -XX:+ZGenerational ...`,但是在未来的版本中,ZGC将会成为默认的垃圾回收器 © 允许规范转载 打赏 赞赏作者 微信 赞
